
CUDA编程
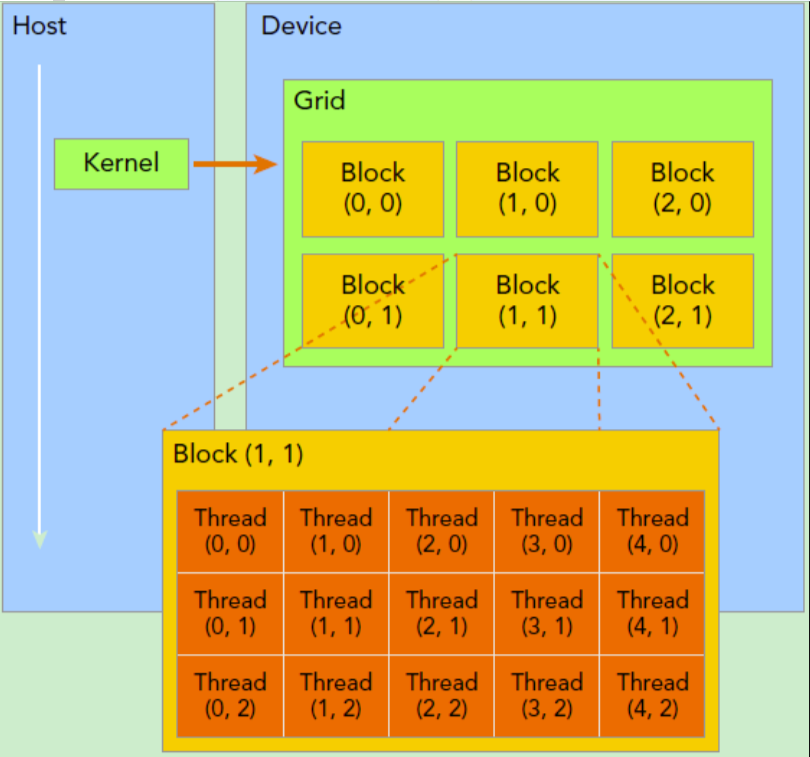
一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次。网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。
kernel在调用时必须通过执行配置<<<grid, block>>>来指定kernel所使用的线程数及结构。
一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,它们都是dim3类型变量,其中blockIdx指明线程所在grid中的位置,而 threadIdx 指明线程所在block中的位置。
举例
dim3 block_dims(16, 16) 定义2D线程块:(16, 16) 表示x方向16个线程,y方向16个线程,共256个线程
dim3 grid_dims(10, 10) 定义2D网格:(10, 10) 表示x方向10个块,y方向10个块,共100个块
gridDim.x,gridDim.y,gridDim.z恒为定义的固定维度
blockDim.x,blockDim.y,blockDim.z恒为定义的固定维度
threadIdx.x,threadIdx.y,threadIdx.z为在block中的索引
blockIdx.x,blockIdx.y,blockIdx.z为在grid中的索引
__global__ void kernel3D3D(float *input, int dataNum)
{
// thread在block中位置计算:
int threadInBlock = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
// block在整个grid中的位置计算:
int blockInGrid = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
// 一个block有多少个线程计算:
int oneBlockSize = blockDim.x*blockDim.y*blockDim.z;
// 位置索引:
int idx = threadInBlock + oneBlockSize*blockInGrid;
}
3D公式
threadIdx.x + threadIdx.y * blockDim.x + threadIdx.z * blockDim.x * blockDim.y + blockDim.x * blockDim.y * blockDim.z * (blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y)
根据3D公式,将其中不需要的维度设置为1,不需要用到索引设置为0,既能获取其它不同维度的公式,去处维度的顺序一般是先Z、再Y
1D情况:

int global_idx = blockIdx.x * blockDim.x + threadIdx.x;
2D情况:
先计算块内偏移,再计算块间偏移
线程在块内的偏移:threadIdx.x + threadIdx.y * blockDim.x(同一行内的线程偏移 + 行数 × 每行线程数)
块在网格内的偏移:(blockIdx.x + blockIdx.y * gridDim.x) * (blockDim.x * blockDim.y)(块的索引 × 每个块的总线程数)
int global_idx = threadIdx.x + threadIdx.y * blockDim.x + blockIdx.x * blockDim.x * blockDim.y + blockIdx.y * gridDim.x * blockDim.x * blockDim.y;
二维线程块二维线程的全局坐标索引: int global_row = blockIdx.y * blockDim.y + threadIdx.y; int global_col = blockIdx.x * blockDim.x + threadIdx.x;
__device__表示从GPU上调用,在GPU上执行
__global__表示从CPU上调用,在GPU上执行,也称为kernel函数
__host__表示在CPU上调用,在CPU上执行
cuda核函数使用<<<>>>形式,用来传递内核函数的执行参数,格式如下:
kernel<<<gridDim,blockDim, memSize, stream>>>(para1, para2,…);
gridDim表示网格的大小,可以为1维,2维或者3维
blockDim表示块的大小,可以为1维,2维或者3维
memSize表示动态分配的共享存储器大小,默认为0
stream表示执行的流,默认位0
para1,para2等为核函数参数
__global__
表示该函数是核函数(Kernel),由CPU调用并在GPU上执行。
调用方式:函数调用时,需要指定 线程块数 和 每个线程块中的线程数,即通过 <<<gridDim, blockDim>>> 语法从主机(Host)启动。
限制:必须返回void类型。
不能是类的成员函数。
通常用于并行计算任务的主体逻辑。
__device__
表示该函数在GPU上执行,且只能由其他__device__函数或__global__函数调用(即仅GPU内部调用)。
可以有返回值
用途:实现GPU内部的辅助函数或工具函数。
限制:无法直接从CPU调用。
#include <stdio.h>
#include <assert.h>
#include <iostream>
#define M 64
#define K 256
#define N 128
#define MAX_ERR 1e-4
__global__ void matrix_vector_multiplication(float* vector_result, float *matrix_a, float *matrix_b, int m_row, int n_col)
{
//__shared__ float temp[M*N];
//extern __shared__ float temp[]; //matrix_vector_multiplication<<<M,N,sizeof(float) * (M * N)>>>
// blockIdx.x => 0代表矩阵的第一行与矩阵B相乘,1代表矩阵的第二行与矩阵B相乘
// blockDim.x => 输出维度,对应矩阵B的col
// threadIdx.x => 当前block内某个线程的ID,就是矩阵B中某列的索引
// Unique tid which can index each single element in the output matrix
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// 上面这一生成索引会有tid超出矩阵边界的风险,因此需要用下面的条件语句加限制
int size_of_the_matrix = m_row*n_col;
if(tid<size_of_the_matrix)
{
for(int i=0;i<K;i++)
{
vector_result[tid]+=matrix_a[blockIdx.x*K+i]*matrix_b[i*N+threadIdx.x];
}
}
//__syncthreads(); // synchronize all threads
}
int main(void)
{
float *x, *y;
float *r;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, M*K*sizeof(float));
cudaMallocManaged(&y, K*N*sizeof(float));
cudaMallocManaged(&r, M*N*sizeof(float));
// initialize x and y arrays on the host
for(int i=0; i<M; i++){
for(int j=0; j<K; j++){
x[i*K+j] = float(j);
}
}
for(int i=0; i<K; i++){
for(int j=0; j<N; j++){
y[i*N+j] = float(i);
}
}
// Run kernel on 1M elements on the GPU
matrix_vector_multiplication<<<M,N>>>(r,x,y,M,N);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
float maxError = 0.0f;
for (int i=0; i <M; i++){
for (int j=0; j<N;j++){
maxError = fmax(maxError, fabs(r[i*N+j]-5559680.0f));
if(maxError!=0.0f)
{
std::cout << "Max error: " << maxError << std::endl;
}
}
}
// Free memory
cudaFree(x);
cudaFree(y);
cudaFree(r);
return 0;
}
实测cpu上的数值计算和gpu上的数值计算在大量累计后可能存在由于硬件差异导致的数值差异
nvcc hello.cu -o hello
nsys profile –stats=true ./hello
Nsight Systems & Nsight Compute
nsys –version ncu –version
ncu –set full –target-processes all -o report ./your_program –args
或者用NVIDIA Nsight Compute GUI直接运行程序得到分析结果