
使用Tensorflow做Prisma
人工智能图片滤镜软件Prisma非常的火,这款图片处理的App 综合了人工神经网络技术(neural networks)和人工智能技术,可以获取著名绘画大师和主要流派的艺术风格,然后对照片进行智能风格化处理,将图片转化为艺术化的效果。
该项目最先是图宾根大学的一篇论文“A Neural Algorithm of Artistic Style”引出,简单来说它是通过卷积神经网络(CNN)学习了一副画的风格,并将这幅画的风格应用到另一幅图片上。
项目地址:https://github.com/harry19902002/image-style-transfor
CVPR文章: Image Style Transfer Using Convolutional Neural Networks
算法原理非常简单,如图
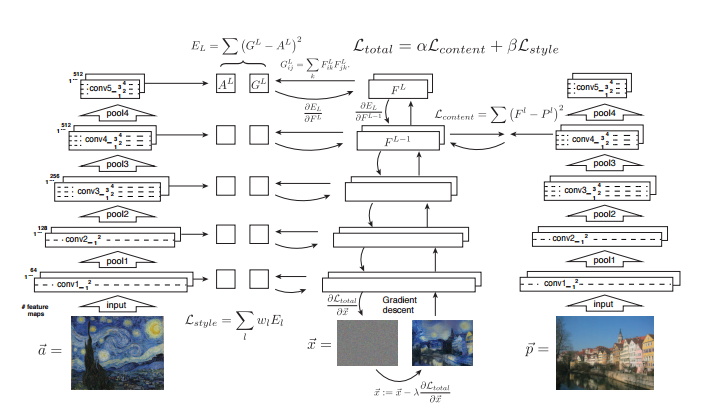
首先选取一个网络,比如VGG16,然后将style image输入网络获得指定layers的feature maps,再将content image输入网络获得指定layer的feature map.这里作者使用了CONTENT_LAYER = ‘relu4_2’,STYLE_LAYERS = (‘relu1_1’, ‘relu2_1’, ‘relu3_1’, ‘relu4_1’, ‘relu5_1’).再随机产生一个相同尺寸高斯白噪声,通过网络获得对应layer的feature maps,然后分别计算content feature map 和style feature map 和高斯白噪声中的对应feature map的loss,loss采用feature map的vector inner product的l2 loss.在代码实现中还加入了一个pixel级的差分loss用于平滑图像.利用梯度下降算法最小化loss更新网络获得的图像就能match content image 和style image了。
如下是我用算法实现的迁移图像效果图。


neural_style.py
import os
import numpy as np
import scipy.misc
from stylize import stylize
import math
from argparse import ArgumentParser
# default arguments
CONTENT_WEIGHT = 5e0 #content loss weight
STYLE_WEIGHT = 1e2 #style loss weight
TV_WEIGHT = 1e2 #smooth loss weight
LEARNING_RATE = 1e2
STYLE_SCALE = 1.0
ITERATIONS = 1000
VGG_PATH = './imagenet-vgg-verydeep-19.mat'
def build_parser():
parser = ArgumentParser()
parser.add_argument('--content',
dest='content', help='content image',
metavar='CONTENT', required=True)
parser.add_argument('--styles',
dest='styles',
nargs='+', help='one or more style images',
metavar='STYLE', required=True)
parser.add_argument('--output',
dest='output', help='output path',
metavar='OUTPUT', required=True)
parser.add_argument('--checkpoint-output',
dest='checkpoint_output', help='checkpoint output format',
metavar='OUTPUT')
parser.add_argument('--iterations', type=int,
dest='iterations', help='iterations (default %(default)s)',
metavar='ITERATIONS', default=ITERATIONS)
parser.add_argument('--width', type=int,
dest='width', help='output width',
metavar='WIDTH')
parser.add_argument('--style-scales', type=float,
dest='style_scales',
nargs='+', help='one or more style scales',
metavar='STYLE_SCALE')
parser.add_argument('--network',
dest='network', help='path to network parameters (default %(default)s)',
metavar='VGG_PATH', default=VGG_PATH)
parser.add_argument('--content-weight', type=float,
dest='content_weight', help='content weight (default %(default)s)',
metavar='CONTENT_WEIGHT', default=CONTENT_WEIGHT)
parser.add_argument('--style-weight', type=float,
dest='style_weight', help='style weight (default %(default)s)',
metavar='STYLE_WEIGHT', default=STYLE_WEIGHT)
parser.add_argument('--style-blend-weights', type=float,
dest='style_blend_weights', help='style blending weights',
nargs='+', metavar='STYLE_BLEND_WEIGHT')
parser.add_argument('--tv-weight', type=float,
dest='tv_weight', help='total variation regularization weight (default %(default)s)',
metavar='TV_WEIGHT', default=TV_WEIGHT)
parser.add_argument('--learning-rate', type=float,
dest='learning_rate', help='learning rate (default %(default)s)',
metavar='LEARNING_RATE', default=LEARNING_RATE)
parser.add_argument('--initial',
dest='initial', help='initial image',
metavar='INITIAL')
parser.add_argument('--print-iterations', type=int,
dest='print_iterations', help='statistics printing frequency',
metavar='PRINT_ITERATIONS')
parser.add_argument('--checkpoint-iterations', type=int,
dest='checkpoint_iterations', help='checkpoint frequency',
metavar='CHECKPOINT_ITERATIONS')
return parser
def main():
parser = build_parser()
options = parser.parse_args()
if not os.path.isfile(options.network):
parser.error("Network %s does not exist. (Did you forget to download it?)" % options.network)
content_image = imread(options.content)
style_images = [imread(style) for style in options.styles]
width = options.width
if width is not None:
new_shape = (int(math.floor(float(content_image.shape[0]) /
content_image.shape[1] * width)), width)
content_image = scipy.misc.imresize(content_image, new_shape)
target_shape = content_image.shape
for i in range(len(style_images)):
style_scale = STYLE_SCALE
if options.style_scales is not None:
style_scale = options.style_scales[i]
style_images[i] = scipy.misc.imresize(style_images[i], style_scale *
target_shape[1] / style_images[i].shape[1])
style_blend_weights = options.style_blend_weights
if style_blend_weights is None:
# default is equal weights
style_blend_weights = [1.0/len(style_images) for _ in style_images]
else:
total_blend_weight = sum(style_blend_weights)
style_blend_weights = [weight/total_blend_weight
for weight in style_blend_weights]
initial = options.initial
if initial is not None:
initial = scipy.misc.imresize(imread(initial), content_image.shape[:2])
if options.checkpoint_output and "%s" not in options.checkpoint_output:
parser.error("To save intermediate images, the checkpoint output "
"parameter must contain `%s` (e.g. `foo%s.jpg`)")
for iteration, image in stylize(
network=options.network,
initial=initial,
content=content_image,
styles=style_images,
iterations=options.iterations,
content_weight=options.content_weight,
style_weight=options.style_weight,
style_blend_weights=style_blend_weights,
tv_weight=options.tv_weight,
learning_rate=options.learning_rate,
print_iterations=options.print_iterations,
checkpoint_iterations=options.checkpoint_iterations
):
output_file = None
if iteration is not None:
if options.checkpoint_output:
output_file = options.checkpoint_output % iteration
else:
output_file = options.output
if output_file:
imsave(output_file, image)
def imread(path):
return scipy.misc.imread(path).astype(np.float)
def imsave(path, img):
img = np.clip(img, 0, 255).astype(np.uint8)
scipy.misc.imsave(path, img)
if __name__ == '__main__':
main()
stylize.py
import vgg
import tensorflow as tf
import numpy as np
from sys import stderr
CONTENT_LAYER = 'relu4_2'
STYLE_LAYERS = ('relu1_1', 'relu2_1', 'relu3_1', 'relu4_1', 'relu5_1')
try:
reduce
except NameError:
from functools import reduce
def stylize(network, initial, content, styles, iterations,
content_weight, style_weight, style_blend_weights, tv_weight,
learning_rate, print_iterations=None, checkpoint_iterations=None):
"""
Stylize images.
This function yields tuples (iteration, image); `iteration` is None
if this is the final image (the last iteration). Other tuples are yielded
every `checkpoint_iterations` iterations.
:rtype: iterator[tuple[int|None,image]]
"""
shape = (1,) + content.shape
style_shapes = [(1,) + style.shape for style in styles]
content_features = {}
style_features = [{} for _ in styles]
# compute content features in feedforward mode
g = tf.Graph()
with g.as_default(), g.device('/gpu:0'), tf.Session() as sess:
image = tf.placeholder('float', shape=shape)
net, mean_pixel = vgg.net(network, image)
content_pre = np.array([vgg.preprocess(content, mean_pixel)])
content_features[CONTENT_LAYER] = net[CONTENT_LAYER].eval(
feed_dict={image: content_pre})
# compute style features in feedforward mode
for i in range(len(styles)):
g = tf.Graph()
with g.as_default(), g.device('/gpu:0'), tf.Session() as sess:
image = tf.placeholder('float', shape=style_shapes[i])
net, _ = vgg.net(network, image)
style_pre = np.array([vgg.preprocess(styles[i], mean_pixel)])
for layer in STYLE_LAYERS:
features = net[layer].eval(feed_dict={image: style_pre})
features = np.reshape(features, (-1, features.shape[3]))
gram = np.matmul(features.T, features) / features.size
style_features[i][layer] = gram
# make stylized image using backpropogation
with tf.Graph().as_default():
if initial is None:
noise = np.random.normal(size=shape, scale=np.std(content) * 0.1)
initial = tf.random_normal(shape) * 0.256
else:
initial = np.array([vgg.preprocess(initial, mean_pixel)])
initial = initial.astype('float32')
image = tf.Variable(initial)
net, _ = vgg.net(network, image)
# content loss
content_loss = content_weight * (2 * tf.nn.l2_loss(
net[CONTENT_LAYER] - content_features[CONTENT_LAYER]) /
content_features[CONTENT_LAYER].size)
# style loss
style_loss = 0
for i in range(len(styles)):
style_losses = []
for style_layer in STYLE_LAYERS:
layer = net[style_layer]
_, height, width, number = map(lambda i: i.value, layer.get_shape())
size = height * width * number
feats = tf.reshape(layer, (-1, number))
gram = tf.matmul(tf.transpose(feats), feats) / size
style_gram = style_features[i][style_layer]
style_losses.append(2 * tf.nn.l2_loss(gram - style_gram) / style_gram.size)
style_loss += style_weight * style_blend_weights[i] * reduce(tf.add, style_losses)
# total variation denoising
tv_y_size = _tensor_size(image[:,1:,:,:])
tv_x_size = _tensor_size(image[:,:,1:,:])
tv_loss = tv_weight * 2 * (
(tf.nn.l2_loss(image[:,1:,:,:] - image[:,:shape[1]-1,:,:]) /
tv_y_size) +
(tf.nn.l2_loss(image[:,:,1:,:] - image[:,:,:shape[2]-1,:]) /
tv_x_size))
# overall loss
loss = content_loss + style_loss + tv_loss
# optimizer setup
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
def print_progress(i, last=False):
stderr.write('Iteration %d/%d\n' % (i + 1, iterations))
if last or (print_iterations and i % print_iterations == 0):
stderr.write(' content loss: %g\n' % content_loss.eval())
stderr.write(' style loss: %g\n' % style_loss.eval())
stderr.write(' tv loss: %g\n' % tv_loss.eval())
stderr.write(' total loss: %g\n' % loss.eval())
# optimization
best_loss = float('inf')
best = None
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
for i in range(iterations):
last_step = (i == iterations - 1)
print_progress(i, last=last_step)
train_step.run()
if (checkpoint_iterations and i % checkpoint_iterations == 0) or last_step:
this_loss = loss.eval()
if this_loss < best_loss:
best_loss = this_loss
best = image.eval()
yield (
(None if last_step else i),
vgg.unprocess(best.reshape(shape[1:]), mean_pixel)
)
def _tensor_size(tensor):
from operator import mul
return reduce(mul, (d.value for d in tensor.get_shape()), 1)
vgg.py
import tensorflow as tf
import numpy as np
import scipy.io
def net(data_path, input_image):
layers = (
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3',
'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3',
'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3',
'relu5_3', 'conv5_4', 'relu5_4'
)
data = scipy.io.loadmat(data_path)
mean = data['normalization'][0][0][0]
mean_pixel = np.mean(mean, axis=(0, 1))
weights = data['layers'][0]
net = {}
current = input_image
for i, name in enumerate(layers):
kind = name[:4]
if kind == 'conv':
kernels, bias = weights[i][0][0][0][0]
# matconvnet: weights are [width, height, in_channels, out_channels]
# tensorflow: weights are [height, width, in_channels, out_channels]
kernels = np.transpose(kernels, (1, 0, 2, 3))
bias = bias.reshape(-1)
current = _conv_layer(current, kernels, bias)
elif kind == 'relu':
current = tf.nn.relu(current)
elif kind == 'pool':
current = _pool_layer(current)
net[name] = current
assert len(net) == len(layers)
return net, mean_pixel
def _conv_layer(input, weights, bias):
conv = tf.nn.conv2d(input, tf.constant(weights), strides=(1, 1, 1, 1),
padding='SAME')
return tf.nn.bias_add(conv, bias)
def _pool_layer(input):
return tf.nn.max_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1),
padding='SAME')
def preprocess(image, mean_pixel):
return image - mean_pixel
def unprocess(image, mean_pixel):
return image + mean_pixel
下载VGG19网络模型:
下载地址:http://www.vlfeat.org/matconvnet/models/beta16/imagenet-vgg-verydeep-19.mat
开始转换
python neural_style.py --content 原始图片文件名 --styles 风格图片文件名 --out 生成图片文件名
#例:
python neural_style.py --content ContentFile.jpg --styles StyleFile.jpg --out OutFile.jpg
项目中还有很多其他参数
--iterations 修改迭代次数(默认为1000)
--content_weight 照片权重
--style_weight 风格图片权重
--learning_rate 学习步长
更多的参数可以通过输入下面代码查找
python neural_style.py --help