
flappyBird DQN
下图是使用的createQNetwork的一部分
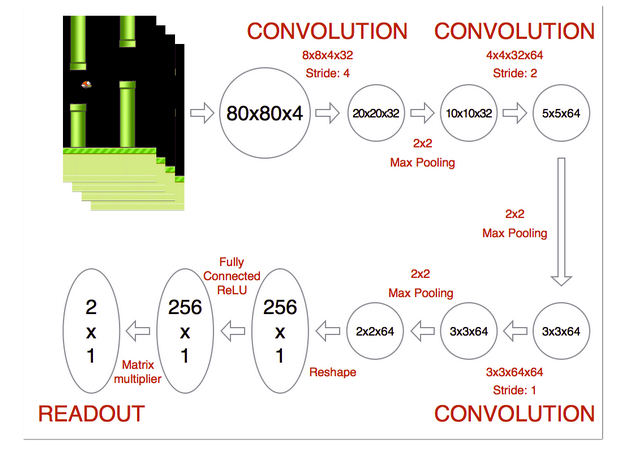
核心算法思想如下

大致算法流程如下
首先随机动作填充replace memory, [state_t, action, reward,state_t+1]
价值网络预测对应state下执行每个动作所获得的feature reward
训练价值网络使得state_t下的feature reward和state_t+1下的feature reward和前一时刻的reward的和逼近
更新replace memory直到整个网络收敛
# FlappyBirdDQN.py
import cv2
import sys
sys.path.append("game/")
import wrapped_flappy_bird as game
from BrainDQN_Nature import BrainDQN
import numpy as np
# preprocess raw image to 80*80 gray image
def preprocess(observation):
observation = cv2.cvtColor(cv2.resize(observation, (80, 80)), cv2.COLOR_BGR2GRAY)
ret, observation = cv2.threshold(observation,1,255,cv2.THRESH_BINARY)
return np.reshape(observation,(80,80,1))
def playFlappyBird():
# Step 1: init BrainDQN
actions = 2 #两个动作
brain = BrainDQN(actions) #构建Q value网络
# Step 2: init Flappy Bird Game
flappyBird = game.GameState()
# Step 3: play game
# Step 3.1: obtain init state
action0 = np.array([1,0]) # do nothing [1,0]自由下降,[0,1]点击上升
observation0, reward0, terminal = flappyBird.frame_step(action0) #初始化获得小鸟图像
observation0 = cv2.cvtColor(cv2.resize(observation0, (80, 80)), cv2.COLOR_BGR2GRAY)
ret, observation0 = cv2.threshold(observation0,1,255,cv2.THRESH_BINARY) #获得游戏屏幕输入
brain.setInitState(observation0) #将初始帧复制4份作为初始state的输入
# Step 3.2: run the game
flag = 1!=0
while True:
action = brain.getAction() 根据currentState获得网络预测Q value然后决策action
nextObservation,reward,terminal = flappyBird.frame_step(action) 根据action更新游戏当前帧
nextObservation = preprocess(nextObservation) 游戏画面处理
brain.setPerception(nextObservation,action,reward,terminal) DQN网络处理
def main():
playFlappyBird()
if __name__ == '__main__':
main()
# BrainDQN_Nature.py
import tensorflow as tf
import numpy as np
import random
from collections import deque
# Hyper Parameters:
FRAME_PER_ACTION = 1
GAMMA = 0.99 # decay rate of past observations
OBSERVE = 100. # timesteps to observe before training
EXPLORE = 200000. # frames over which to anneal epsilon
FINAL_EPSILON = 0#0.001 # final value of epsilon
INITIAL_EPSILON = 0#0.01 # starting value of epsilon
REPLAY_MEMORY = 50000 # number of previous transitions to remember
#REPLAY_MEMORY = 50 # number of previous transitions to remember
BATCH_SIZE = 32 # size of minibatch
UPDATE_TIME = 100
class BrainDQN:
def __init__(self,actions):
# init replay memory
self.replayMemory = deque()
# init some parameters
self.timeStep = 0
self.epsilon = INITIAL_EPSILON
self.actions = actions
# init Q network, this is for current state
self.stateInput, self.QValue, self.W_conv1, self.b_conv1, self.W_conv2, \
self.b_conv2, self.W_conv3, self.b_conv3, self.W_fc1, \
self.b_fc1, self.W_fc2, self.b_fc2 = self.createQNetwork()
# init Target Q Network, this is for next state and will update
self.stateInputT,self.QValueT,self.W_conv1T,self.b_conv1T,self.W_conv2T,self.b_conv2T,self.W_conv3T,self.b_conv3T,self.W_fc1T,self.b_fc1T,self.W_fc2T,self.b_fc2T = self.createQNetwork()
self.copyTargetQNetworkOperation = \
[ self.W_conv1T.assign(self.W_conv1), \
self.b_conv1T.assign(self.b_conv1), \
self.W_conv2T.assign(self.W_conv2), \
self.b_conv2T.assign(self.b_conv2), \
self.W_conv3T.assign(self.W_conv3), \
self.b_conv3T.assign(self.b_conv3), \
self.W_fc1T.assign(self.W_fc1), \
self.b_fc1T.assign(self.b_fc1), \
self.W_fc2T.assign(self.W_fc2), \
self.b_fc2T.assign(self.b_fc2) ]
self.createTrainingMethod()# create the network completly
# saving and loading networks
self.saver = tf.train.Saver()
self.session = tf.InteractiveSession()
self.session.run(tf.initialize_all_variables()) # init all the netwotk
checkpoint = tf.train.get_checkpoint_state("saved_networks")
if checkpoint and checkpoint.model_checkpoint_path:
self.saver.restore(self.session, checkpoint.model_checkpoint_path)
print "Successfully loaded:", checkpoint.model_checkpoint_path
else:
print "Could not find old network weights"
def createQNetwork(self):
# network weights
W_conv1 = self.weight_variable([8,8,4,32])
b_conv1 = self.bias_variable([32])
W_conv2 = self.weight_variable([4,4,32,64])
b_conv2 = self.bias_variable([64])
W_conv3 = self.weight_variable([3,3,64,64])
b_conv3 = self.bias_variable([64])
W_fc1 = self.weight_variable([1600,512])
b_fc1 = self.bias_variable([512])
W_fc2 = self.weight_variable([512,self.actions])
b_fc2 = self.bias_variable([self.actions])
# input layer
stateInput = tf.placeholder("float",[None,80,80,4])
# hidden layers
h_conv1 = tf.nn.relu(self.conv2d(stateInput,W_conv1,4) + b_conv1)
h_pool1 = self.max_pool_2x2(h_conv1)
h_conv2 = tf.nn.relu(self.conv2d(h_pool1,W_conv2,2) + b_conv2)
h_conv3 = tf.nn.relu(self.conv2d(h_conv2,W_conv3,1) + b_conv3)
h_conv3_flat = tf.reshape(h_conv3,[-1,1600])
h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat,W_fc1) + b_fc1)
# Q Value layer
QValue = tf.matmul(h_fc1,W_fc2) + b_fc2
print 'Qvalue shap = {} '.format(QValue.get_shape())
return stateInput, QValue, W_conv1, b_conv1, \
W_conv2, b_conv2, W_conv3, b_conv3, \
W_fc1, b_fc1, W_fc2, b_fc2
def copyTargetQNetwork(self):
self.session.run(self.copyTargetQNetworkOperation)
def createTrainingMethod(self):
self.actionInput = tf.placeholder("float",[None,self.actions]) #当前状态的action
self.yInput = tf.placeholder("float", [None]) # feature reward
Q_Action = tf.reduce_sum(tf.mul(self.QValue, self.actionInput), reduction_indices = 1) #当前状态的Q value
self.cost = tf.reduce_mean(tf.square(self.yInput - Q_Action)) #cost
self.trainStep = tf.train.AdamOptimizer(1e-6).minimize(self.cost)
def trainQNetwork(self):
#Step 1: obtain random minibatch from replay memory
minibatch = random.sample(self.replayMemory,BATCH_SIZE)
state_batch = [data[0] for data in minibatch]
action_batch = [data[1] for data in minibatch]
reward_batch = [data[2] for data in minibatch]
nextState_batch = [data[3] for data in minibatch]
# Step 2: calculate y
y_batch = []
# get the each state's QV
QValue_batch = self.QValueT.eval(feed_dict={self.stateInputT:nextState_batch}) #下一个state的image输入target Q network
for i in range(0,BATCH_SIZE): #计算feature reward
terminal = minibatch[i][4]
if terminal:
y_batch.append(reward_batch[i])
else:
y_batch.append(reward_batch[i] + GAMMA * np.max(QValue_batch[i]))
self.trainStep.run(feed_dict={
self.yInput : y_batch,
self.actionInput : action_batch,
self.stateInput : state_batch
}) #根据当前state的image的action获得的reward和feature reward计算loss
# save network every 100000 iteration
if self.timeStep % 10000 == 0:
self.saver.save(self.session, 'saved_networks/' + 'network' + '-dqn', global_step = self.timeStep)
if self.timeStep % UPDATE_TIME == 0: #每隔一定次数用Q Network更新Target Network
self.copyTargetQNetwork()
def setPerception(self,nextObservation,action,reward,terminal):
#newState = np.append(nextObservation,self.currentState[:,:,1:],axis = 2)
newState = np.append(self.currentState[:,:,1:],nextObservation,axis = 2)
self.replayMemory.append((self.currentState,action,reward,newState,terminal))
#print 'replayMemory shap = {}'.format(self.replayMemory.shape)
if len(self.replayMemory) > REPLAY_MEMORY: #保留最新的replayMemory
self.replayMemory.popleft()
if self.timeStep > OBSERVE:
# Train the network
self.trainQNetwork()
# print info
state = ""
if self.timeStep <= OBSERVE:
state = "observe"
elif self.timeStep > OBSERVE and self.timeStep <= OBSERVE + EXPLORE:
state = "explore"
else:
state = "train"
print "TIMESTEP", self.timeStep, "/ STATE", state, \
"/ EPSILON", self.epsilon
self.currentState = newState
self.timeStep += 1
def getAction(self):
QValue = self.QValue.eval(feed_dict= {self.stateInput:[self.currentState]})[0]
action = np.zeros(self.actions)
action_index = 0
if self.timeStep % FRAME_PER_ACTION == 0:
if random.random() <= self.epsilon:
action_index = random.randrange(self.actions)
action[action_index] = 1
else:
action_index = np.argmax(QValue)
action[action_index] = 1
else:
action[0] = 1 # do nothing
# change episilon
if self.epsilon > FINAL_EPSILON and self.timeStep > OBSERVE:
self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON)/EXPLORE
return action
def setInitState(self,observation):
# observation.shape => [80. 80, 1] curr
self.currentState = np.stack((observation, observation, observation, observation), axis = 2)
print "currentState = {}".format(self.currentState.shape)
def weight_variable(self,shape):
initial = tf.truncated_normal(shape, stddev = 0.01)
return tf.Variable(initial)
def bias_variable(self,shape):
initial = tf.constant(0.01, shape = shape)
return tf.Variable(initial)
def conv2d(self,x, W, stride):
return tf.nn.conv2d(x, W, strides = [1, stride, stride, 1], padding = "SAME")
def max_pool_2x2(self,x):
return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = "SAME")