
Qwen3-RL
众所周知模型的部署必然绕不开模型量化这一步,因为现在的模型实在太大了,在这篇博客里我们将介绍一种结合强化学习的端到端量化感知训练方案,能更好的对齐最终的使用场景。确保模型的量化方向和最终使用的方式保持完全一致。这是目前主流的PTQ量化比如GPTQ或AWQ方案所不具备的,后量化的方案本质上依然在估计数据的分布,而我们的方案优化的是量化后模型的生成分布是否符合用户偏好,更贴近最终优化目标。
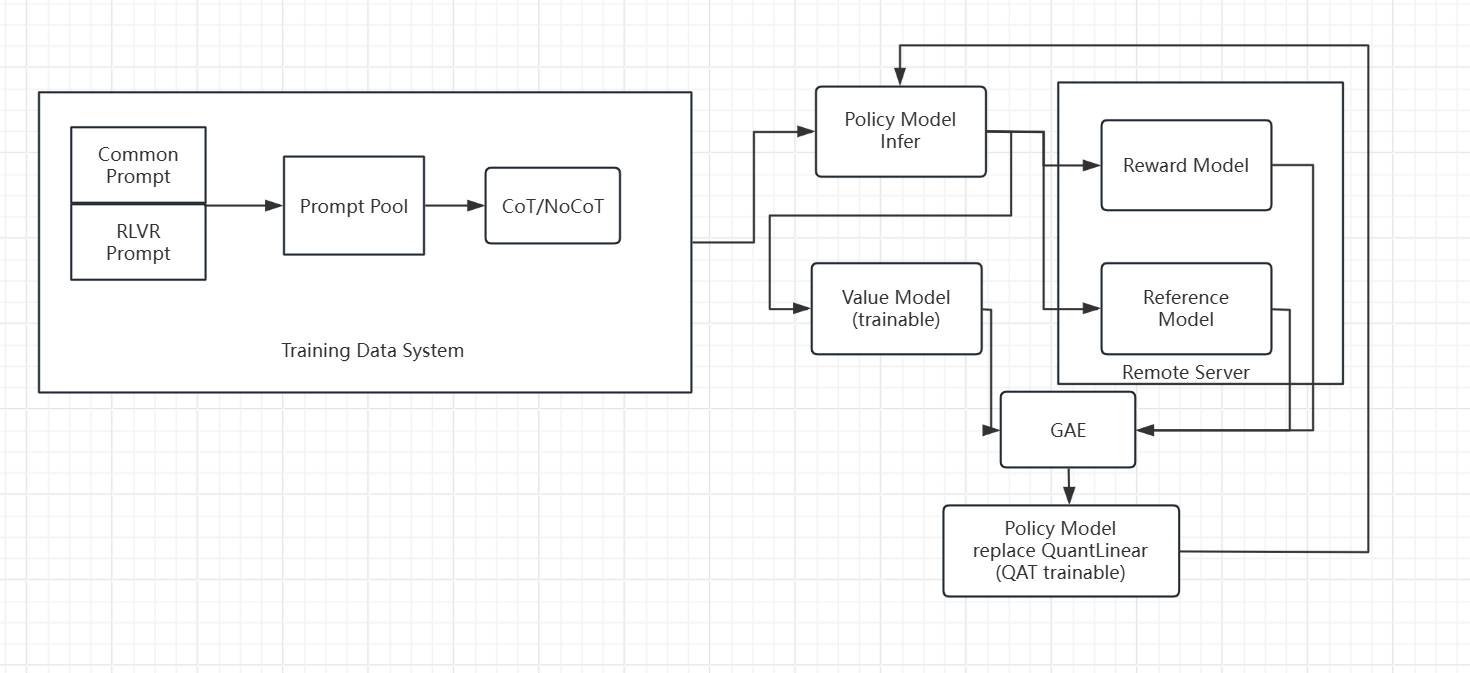
思路也很简单,基于上一篇博客的工作,使用量化感知训练(QAT)方法训练最终的模型,由于最终的目标是Policy model,所以只要将QuantLinear的op插入Policy model替换原来的nn.Linear即可,所有其他部分依然可以保持不变,另外为了同时量化Embedding层,我们同时设计了一个QuantEmbedding层替换原来的nn.Embedding.量化感知训练过程的梯度传递问题可以依靠STE(Straight-Through Estimator)解决。
通过这个方案最终能实现模型的端到端量化感知强化学习,能集成上篇所述强化学习的优点,同时把优化目标和部署对齐。
| IFEval(EN) | instruct_follow(ZH) | KBQA | RGB | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| strict prompt | strict instruction | loose prompt | loose instruction | all average | per average | TP | FP | TN | FN | 检索en | 拒答en | 整合en | 检索zh | 拒答zh | 整合zh | ||||
| Qwen3-4B | 0.807 | 0.864 | 0.842 | 0.889 | 59.01 | 63.38 | 196 | 86 | 197 | 62 | 0.97 | 0.39 | 0.84 | 0.95 | 0.2 | 0.82 | |||
| Qwen3-4B-QAT-GRPO | 0.76 | 0.84 | 0.817 | 0.88 | 61.39 | 65.49 | 239 | 86 | 197 | 20 | 0.96 | 0.82 | 0.89 | 0.94 | 0.54 | 0.86 | |||
| Qwen3-4B-GPTQ | 0.807 | 0.86 | 0.84 | 0.89 | 59.01 | 64.63 | 178 | 97 | 186 | 81 | 0.96 | 0.38 | 0.82 | 0.95 | 0.35 | 0.83 | |||
| Qwen3-4B-QAT-lite-cold-start | 0.619 | 0.713 | 0.658 | 0.748 | 58.22 | 61.14 | 221 | 87 | 196 | 36 | 0.95 | 0.62 | 0.76 | 0.94 | 0.61 | 0.77 | |||
| Qwen3-4B-QAT-heavy-cold-start | 0.674 | 0.761 | 0.739 | 0.808 | 58.22 | 60.33 | 212 | 55 | 228 | 46 | 0.94 | 0.64 | 0.77 | 0.94 | 0.62 | 0.8 | |||
| Qwen3-1.7B-250424 | 0.704 | 0.778 | 0.741 | 0.811 | 54.06 | 59.56 | 223 | 221 | 62 | 24 | 0.89 | 0.74 | 0.73 | 0.86 | 0.82 | 0.78 | |||
| Qwen3-1.7B-QAT-GRPO | 0.64 | 0.732 | 0.686 | 0.77 | 50.3 | 54.75 | 230 | 118 | 165 | 29 | 0.89 | 0.7 | 0.76 | 0.91 | 0.77 | 0.76 | |||
| Qwen3-1.7B-250424-GPTQ | 0.63 | 0.72 | 0.66 | 0.756 | 48.12 | 53.53 | 228 | 229 | 54 | 20 | 0.9 | 0.3 | 0.73 | 0.91 | 0.61 | 0.71 | |||
| Qwen3-1.7B-QAT-lite-cold-start | 0.499 | 0.583 | 0.554 | 0.642 | 39.01 | 42.13 | 76 | 49 | 234 | 182 | 0.89 | 0.05 | 0.61 | 0.89 | 0.37 | 0.65 | |||
| Qwen3-1.7B-QAT-heavy-cold-start | 0.46 | 0.57 | 0.495 | 0.611 | 45.94 | 47.68 | 119 | 63 | 220 | 139 | 0.9 | 0.23 | 0.61 | 0.9 | 0.52 | 0.67 |
实验结果可见基于QAT的RL要远远好于直接QAT的SFT,这种情况在越小的模型下越明显。同时和GPTQ的方法相比,除了Qwen3-4B的IFEVal结果比GPTQ方法略有下降,其他所有测试都得到了提升,并且同时完成了拒答能力的定向增强和保持了通用能力。
彩蛋,在一些普通的测试中能发现PTQ量化会有一些奇怪的生成现象,比如语言混杂,截断,重复生成等现象。而通过QAT-RL这种现象能大幅下降,主要原因依然是PTQ通过先验数据估计量化参数,这和模型生成存在不匹配,而我们的方案通过最终的生成行为训练量化参数,这和模型的最终使用场景完全匹配。