
tensorflow转onnx
tensorflow转onnx比较简单用tf2onnx这个工具,记录下最近在用之前训练好的yolo模型tensorflow转好的onnx模型上要转支持动态batchsize模型时候遇到的问题
下图是tensorflow模型转好的onnx模型的输入输出以及一些有问题节点
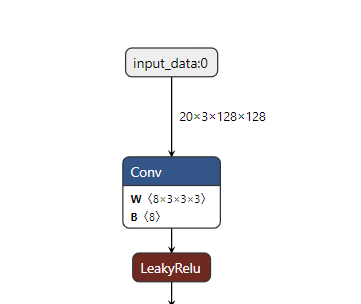
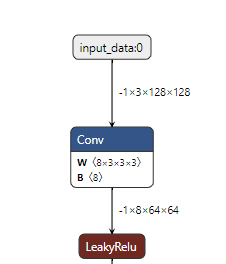
首先第一点输入输出是batch=20的
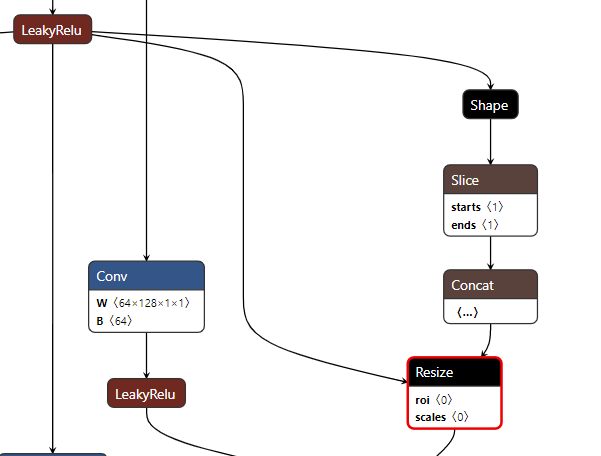
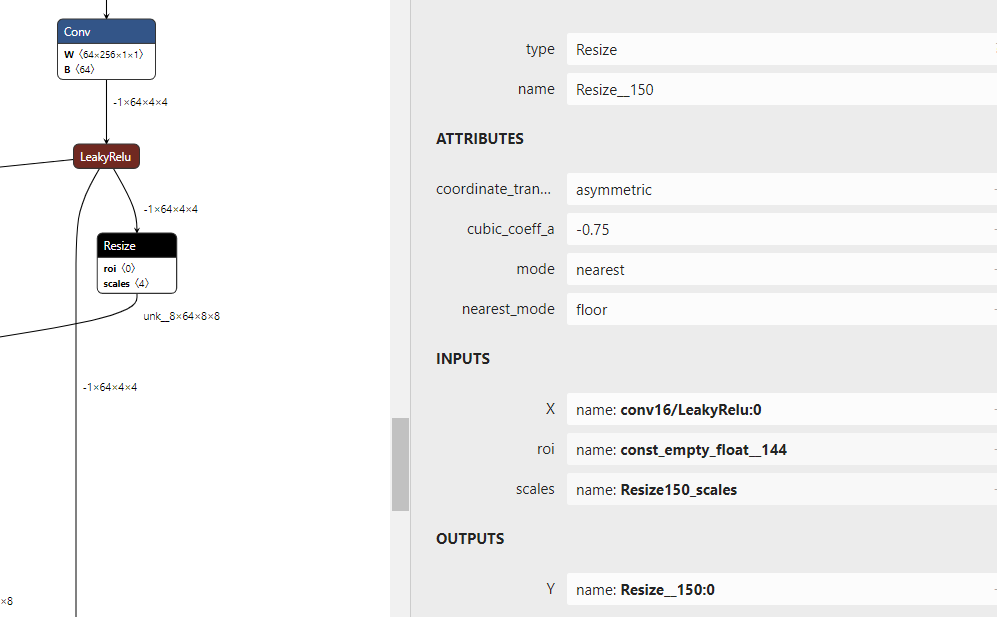
第二点resize的模型和pytorch转出来的模型不一样,size是额外通过tensor获取的而不是写到resize的参数里
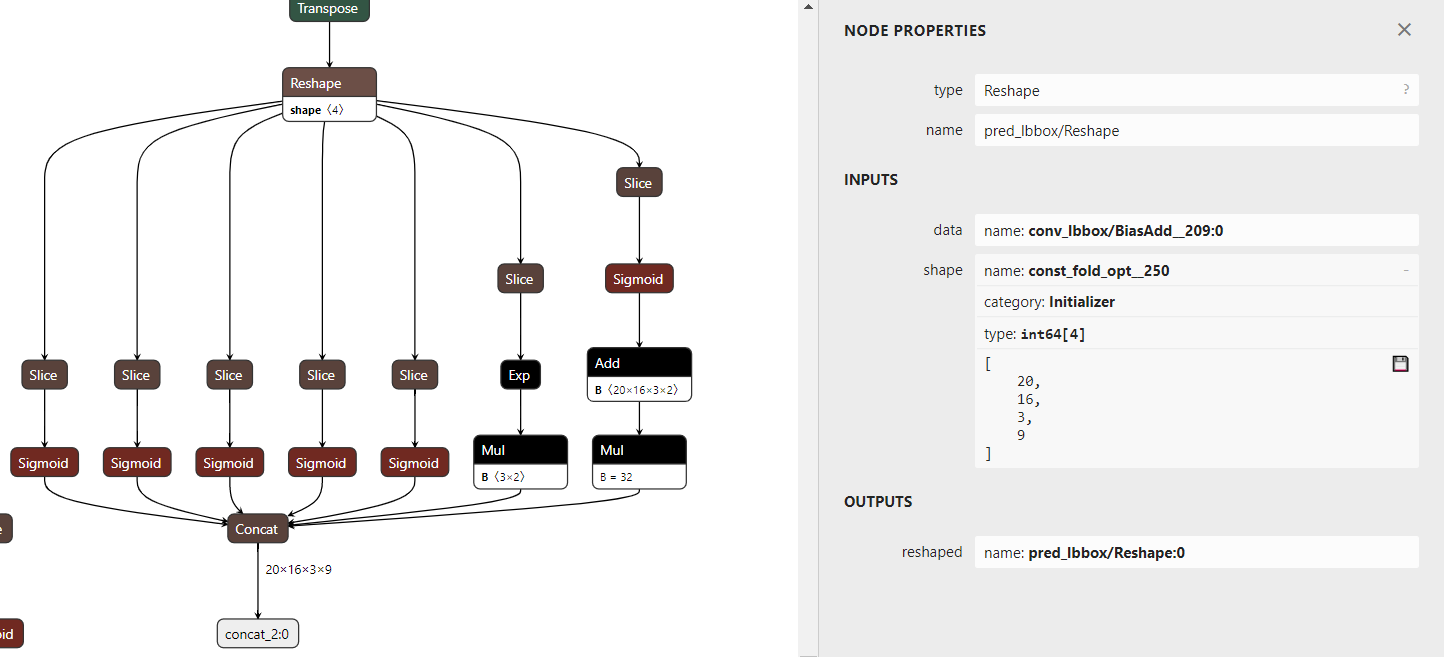
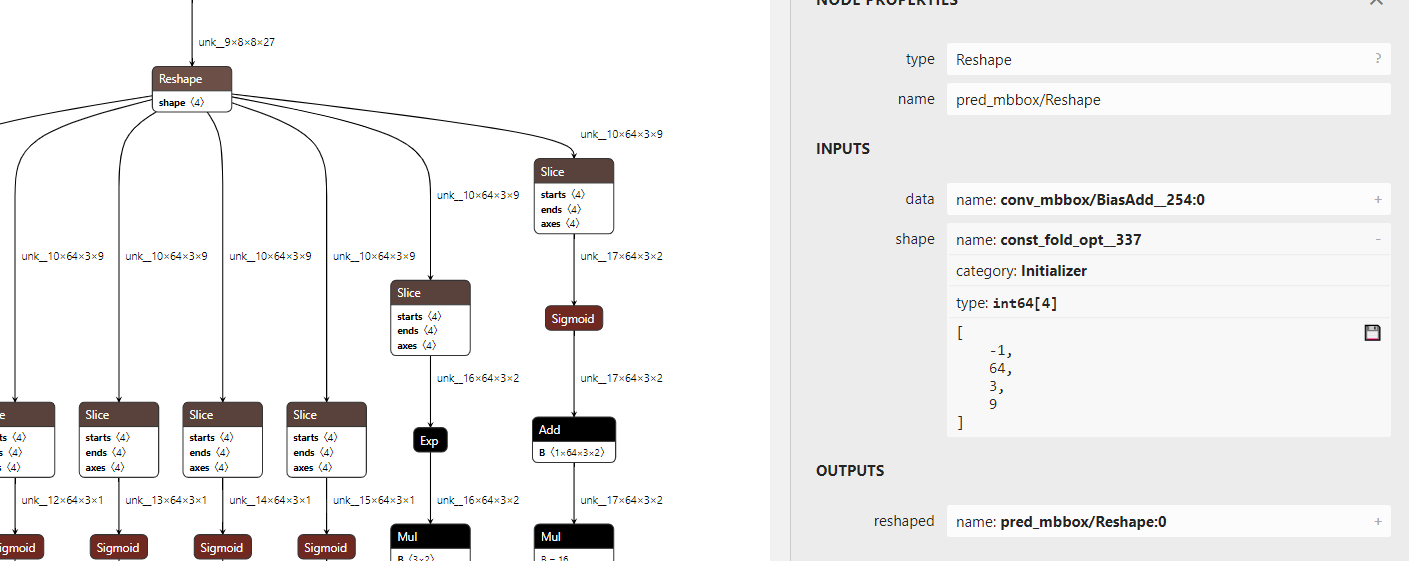
第三点这个reshape的shape参数batch也是通过获取tensor属性强制写死的,无法通过后续改输入的batch来改变
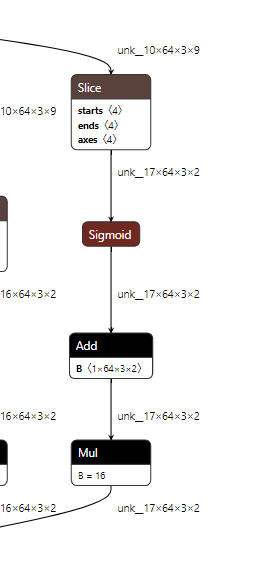
第四点是yolo最后decode的时候每个解码出来的dxdy要加上对应格子处的坐标点,在第二张图有个Add B仔细查看shape是20x16x3x2
也就是这几个点阻碍了tf生成的onnx模型往动态batchsize转换。
解决第一点非常简单,手动改写onnx输入输出节点batch维度为-1
dim_proto0 = model.graph.input[0].type.tensor_type.shape.dim[0]
dim_proto0.dim_param = "-1"
dim_proto_0 = model.graph.output[0].type.tensor_type.shape.dim[0]
dim_proto_1 = model.graph.output[1].type.tensor_type.shape.dim[0]
dim_proto_2 = model.graph.output[2].type.tensor_type.shape.dim[0]
dim_proto_0.dim_param = "-1"
dim_proto_1.dim_param = "-1"
dim_proto_2.dim_param = "-1"
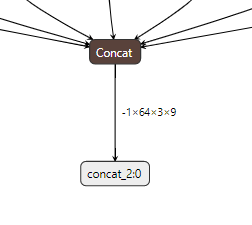
解决第二点,比较麻烦,需要把tf.image.resize_nearest_neighbor对应的resize操作删除掉,然后在原有位置插入torch类似的resize op,首先找到resize节点的id号,删除这个node id. 手写一个新的reisze操作,给scale参数赋值resize的shape,对接上原来resize op的输入输出连接,将initializer参数添加到graph
if node[i].op_type=="Resize" and node[i].name=="Resize__150":
print(i)
rois = np.zeros(shape=(0)).astype(np.float32)
rois_initializer_tensor_name = "Resize150_rois"
rois_initializer_tensor = create_initializer_tensor(name=rois_initializer_tensor_name, tensor_array=rois, data_type=onnx.TensorProto.FLOAT)
scales=np.array([1,1,2,2]).astype(np.float32)
scales_initializer_tensor_name = "Resize150_scales"
scales_initializer_tensor = create_initializer_tensor(name=scales_initializer_tensor_name, tensor_array=scales, data_type=onnx.TensorProto.FLOAT)
new_node = onnx.helper.make_node(name="Resize__150",
op_type="Resize",
inputs=["conv16/LeakyRelu:0",rois_initializer_tensor_name,scales_initializer_tensor_name],
outputs=["Resize__150:0"],
mode="nearest",
coordinate_transformation_mode="asymmetric",
cubic_coeff_a=-0.75,
nearest_mode="floor",)
graph.node.remove(node[i])
graph.initializer.append(rois_initializer_tensor)
graph.initializer.append(scales_initializer_tensor)
graph.node.insert(i, new_node)
解决第三点是在tensorflow代码里面用batch=1代替20,然后由broadcast机制完成相加
解决第四点是强制修改reshape的batch维度为-1
for key, init in enumerate(model.graph.initializer):
print(init.name)
if init.name in ['const_fold_opt__327','const_fold_opt__337','const_fold_opt__338']:
np_data = onnx.numpy_helper.to_array(init)
np_new_data = np.array([-1,np_data[1],np_data[2],np_data[3]],dtype=np.int64)
tensor = onnx.numpy_helper.from_array(np_new_data,init.name)
model.graph.initializer[key].CopyFrom(tensor)
看我写的辛苦求打赏啊!!!有学术讨论和指点请加微信manutdzou,注明
