
Qwen3-RL
众所周知,大模型的训练步骤主要包括第一步预训练,第二步SFT,第三步RL。目前主流的开源Instruct模型基本上遵循这条路径,所以我们能得到的开源模型一般是一个经过强化学习后的模型。
对于模型的SFT训练,可以说只要有卡就能进行几乎没有门槛。一般就是针对业务的需求收集相关的数据做好Query-Answer对给到模型训练完成即可。如果我们只需要定向调优这一步足矣。然而在实践中我们发现通过定向调优后的模型能在收集的SFT数据上提升性能,然而对于原本的通用能力有非常明显的损害。
有同学可能会说那就加配比增加通用数据,这样的实验怎么可能被遗漏呢,然而遗憾的是通用能力依旧明显的损害,而且是训练的step越多降低的越厉害。
可能又有同学说肯定是收集的通用数据质量太低,然而事实是即使强如DeepSeek发布的SFT模型DeepSeek-R1-0528-Qwen3-8B,DeepSeek-R1-Distill-Qwen-7B在我们内部构建的指令跟随,KBQA等通用场景任务上都不如基于对应的Instruct模型。另外实验中发现即使拿极其少量的几百条数据用很小很小的learning rate SFT模型几个step,测试后依然能看到显著的整体性能下降。所以再把SFT模型性能下降归咎于数据质量的高低似乎不是很有道理。特别是综合发现不仅仅Qwen模型有这样的现象,Llama也有类似的现象。
所以一定是有本质的原因导致了这样的现象,博主在此给出一种未经可靠验证的猜测。其实Instruct模型从预训练到SFT到RL经历了不同的优化目标。预训练阶段主要是世界知识的注入阶段,这一步也是整个模型最重要的阶段,决定了模型的上限。第二步SFT是指令跟随阶段,通过让模型学习Query-Answer来教会模型遵循Query的要求回答问题。第三步RL则是人类偏好回答对齐。
具体到训练优化目标,第一步和第二步本质上都是next token prediction阶段,优化目标是最小化信息熵,模型只管给定数据的拟合,不管不良路径生成的抑制。而RL阶段一般采用PPO,GRPO这种强化学习算法,优化目标是最大化奖励期望。
在对强化学习阶段的观察可以发现,模型的行为在信息熵上是缓慢增加到一个水平的,很低的信息熵往往预示着RL训练阶段的失败,所以才有了Fine-Tuning Language Models from Human Preferences预设KL target这种人为鼓励增大信息熵的行为。所以可以说RL的优化目标是将模型的信息熵提高到一个水平保持输出的多样性并和人类偏好对齐。这篇文章THE CURIOUS CASE OF NEURAL TEXT DeGENERATION似乎也印证了这样的观点,人类的偏好并不总是朝着信息熵最小化的方向生成文字序列的。
所以对于一个Instruct模型,它本身已经收敛到一个比SFT时候信息熵要稍高的阶段,再对它接着SFT压低模型的信息熵,必然导致优化方向偏移,模型性能的下降。
以下,我们基于这些猜想去设计我们的定向调优目标,希望得到一个模型既能保持原有的通用能力不损失,又能在模型欠缺的能力上有极大的提升。所以如果发现模型在定向能力上较弱就接着强化学习,如果模型完全不具备定向能力,可以少量在定向数据上cold start SFT获得能力然后接着强化学习。
因此我们设计了如下一套训练流程,基本上目前的开源RL 框架都有类似的功能。然而为了可定制性和自由度,我从最基础的TRL库出发,借鉴了其他开源RL框架的思想完全手搓了下面的训练框架。
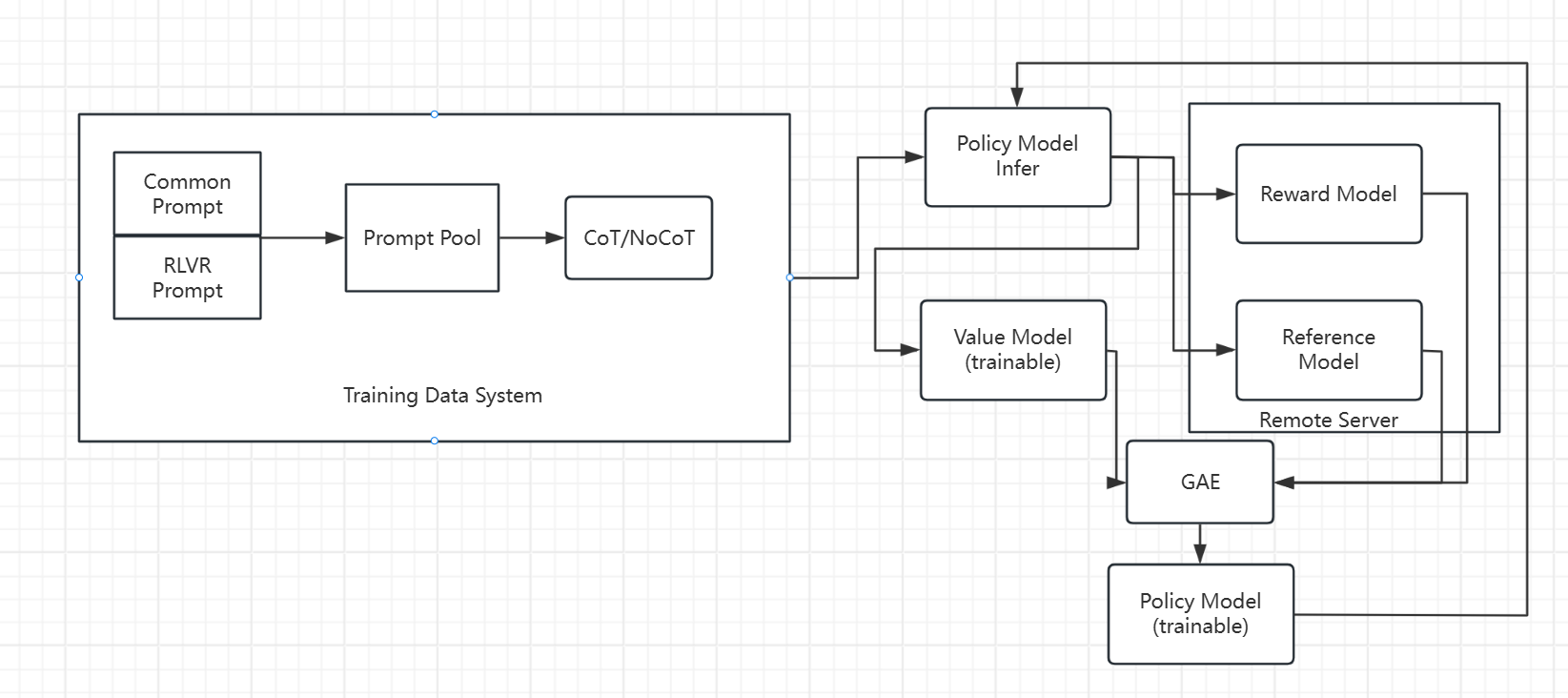
首先训练数据由收集的通用prompt和带可验证答案的prompt组成,比例差不多9:1,混合组成prompt pool。在数据生成方面按5%比例由think模板驱动模型生成CoT的答案,95%比例生成non-CoT的答案。
整个训练流程基于单节点8-A800,人为划分7-A800用于训练,1-A800用于推理。所有模型模块,Policy+Value model是全参数可训练划分到7-A800,Policy model还有一个基于vllm的推理映射单独使用1-A800卡。Reward Model和Reference Model以API的形式通过额外计算资源提供。通过这种设计我们可以尽可能减少对硬件的最小开销,同时保证尽可能大和长的生成采样。我们设置per device batch size为4,每条数据采样16个轨迹,采样长度为2K,同时只收集得分最低的2条和最高的2条组成group送给Policy模型进行RL训练。奖励得分的归一化基于16条数据作归一化。
Reward系统由Neural Base和RLVR Base组成,Neural Base主要处理通用数据的奖励信号,这个模型我们采用了基于Gemma-2-27B的多信号聚合的SequenceClassification和BT rule来训练,RLVR Base我们收集了尽可能多的开源RLVR数据,对于每个数据分别由各自的规则给与奖励信号。
我们主要对Qwen3-1.7B和Qwen3-4B进行了实验。
| IFEval(EN) | instruct_follow(ZH) | KBQA | RGB | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| strict prompt | strict instruction | loose prompt | loose instruction | all average | per average | TP | FP | TN | FN | 检索en | 拒答en | 整合en | 检索zh | 拒答zh | 整合zh | ||||
| Qwen3-4B | 0.807 | 0.864 | 0.842 | 0.889 | 59.01 | 63.38 | 196 | 86 | 197 | 62 | 0.97 | 0.39 | 0.84 | 0.95 | 0.2 | 0.82 | |||
| Qwen3-4B-SFT-lite-cold-start | 0.672 | 0.75 | 0.722 | 0.79 | 59.2 | 62.59 | 192 | 39 | 224 | 66 | 0.97 | 0.57 | 0.73 | 0.92 | 0.5 | 0.82 | |||
| Qwen3-4B-SFT-heavy-cold-start | 0.669 | 0.763 | 0.71 | 0.798 | 60.99 | 64.03 | 153 | 23 | 260 | 106 | 0.96 | 0.57 | 0.76 | 0.95 | 0.56 | 0.82 | |||
| Qwen3-4B-ppo(from Qwen3-4B) | 0.829 | 0.883 | 0.859 | 0.905 | 63.56 | 67.48 | 238 | 66 | 217 | 20 | 0.93 | 0.91 | 0.79 | 0.94 | 0.67 | 0.79 | |||
| Qwen3-1.7B-250424 | 0.704 | 0.778 | 0.741 | 0.811 | 54.06 | 59.56 | 223 | 221 | 62 | 24 | 0.89 | 0.74 | 0.73 | 0.86 | 0.82 | 0.78 | |||
| Qwen3-1.7B-ppo(from Qwen3-1.7B) | 0.691 | 0.779 | 0.73 | 0.81 | 55.64 | 61.2 | 214 | 71 | 212 | 44 | 0.89 | 0.8 | 0.7 | 0.87 | 0.78 | 0.72 |
我们采用PPO算法,混合业务数据和通用数据,模型参数用Instruct模型作为起点,主要目的是提升模型在KBQA相关检索的回答和非相关检索拒答的能力。原始模型在拒答能力上都偏弱。对比实验包括基于SFT的少量数据和大量数据微调,SFT使用数据和RL同源,数据的答案由DeepSeek生成并处理得到。
从上面结果可见,不管训练step的多少,SFT对模型有很大的负面影响。而通过持续RL,在保持中英文指令跟随能力上,4B的模型有了明显的提升,1.7B模型保持了误差内的能力维持。在我们关注的业务KBQA数据上,算法大幅提升了4B模型的正答和拒答能力,在1.7B上大幅提升了拒答能力平衡了原始模型偏向正答的倾向,同时维持了通用能力。
总结,继续强化学习是目前想要定向调优同时希望维持或继续提升模型通用能力的可靠方案。SFT很难同时做到定向调优和维持通用能力。