
Caffe使用教程
数据层及参数
要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个层(layer)构成,每一层又由许多参数组成。所有的参数都定义在caffe.proto这个文件中。要熟练使用caffe,最重要的就是学会配置文件(prototxt)的编写。
层有很多种类型,比如Data,Convolution,Pooling等,层之间的数据流动是以Blobs的方式进行。
今天我们就先介绍一下数据层.
数据层是每个模型的最底层,是模型的入口,不仅提供数据的输入,也提供数据从Blobs转换成别的格式进行保存输出。通常数据的预处理(如减去均值, 放大缩小, 裁剪和镜像等),也在这一层设置参数实现。
数据来源可以来自高效的数据库(如LevelDB和LMDB),也可以直接来自于内存。如果不是很注重效率的话,数据也可来自磁盘的hdf5文件和图片格式文件。
所有的数据层的都具有的公用参数:先看示例
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mean_file: "examples/cifar10/mean.binaryproto"
}
data_param {
source: "examples/cifar10/cifar10_train_lmdb"
batch_size: 100
backend: LMDB
}
}
name: 表示该层的名称,可随意取
-type: 层类型,如果是Data,表示数据来源于LevelDB或LMDB。根据数据的来源不同,数据层的类型也不同(后面会详细阐述)。一般在练习的时候,我们都是采用的LevelDB或LMDB数据,因此层类型设置为Data。
-top或bottom: 每一层用bottom来输入数据,用top来输出数据。如果只有top没有bottom,则此层只有输出,没有输入。反之亦然。如果有多个top或多个bottom,表示有多个blobs数据的输入和输出。
-data 与 label: 在数据层中,至少有一个命名为data的top。如果有第二个top,一般命名为label。 这种(data,label)配对是分类模型所必需的。
-include: 一般训练的时候和测试的时候,模型的层是不一样的。该层(layer)是属于训练阶段的层,还是属于测试阶段的层,需要用include来指定。如果没有include参数,则表示该层既在训练模型中,又在测试模型中。
-Transformations: 数据的预处理,可以将数据变换到定义的范围内。如设置scale为0.00390625,实际上就是1/255, 即将输入数据由0-255归一化到0-1之间
其它的数据预处理也在这个地方设置:
transform_param {
scale: 0.00390625
mean_file_size: "examples/cifar10/mean.binaryproto"
# 用一个配置文件来进行均值操作
mirror: 1 # 1表示开启镜像,0表示关闭,也可用ture和false来表示
# 剪裁一个 227*227的图块,在训练阶段随机剪裁,在测试阶段从中间裁剪
crop_size: 227
}
后面的data_param部分,就是根据数据的来源不同,来进行不同的设置。
1、数据来自于数据库(如LevelDB和LMDB)
层类型(layer type):Data
必须设置的参数:
-source: 包含数据库的目录名称,如examples/mnist/mnist_train_lmdb
-batch_size: 每次处理的数据个数,如64
可选的参数:
-rand_skip: 在开始的时候,路过某个数据的输入。通常对异步的SGD很有用。
-backend: 选择是采用LevelDB还是LMDB, 默认是LevelDB.
示例:
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_train_lmdb"
batch_size: 64
backend: LMDB
}
}
2、数据来自于内存
层类型:MemoryData
必须设置的参数:
-batch_size:每一次处理的数据个数,比如2
-channels:通道数
-height:高度
-width: 宽度
示例:
layer {
top: "data"
top: "label"
name: "memory_data"
type: "MemoryData"
memory_data_param{
batch_size: 2
height: 100
width: 100
channels: 1
}
transform_param {
scale: 0.0078125
mean_file: "mean.proto"
mirror: false
}
}
3、数据来自于HDF5
层类型:HDF5Data
必须设置的参数:
-source: 读取的文件名称
-batch_size: 每一次处理的数据个数
示例:
layer {
name: "data"
type: "HDF5Data"
top: "data"
top: "label"
hdf5_data_param {
source: "examples/hdf5_classification/data/train.txt"
batch_size: 10
}
}
4、数据来自于图片
层类型:ImageData
必须设置的参数:
-source: 一个文本文件的名字,每一行给定一个图片文件的名称和标签(label)
-batch_size: 每一次处理的数据个数,即图片数
可选参数:
-rand_skip: 在开始的时候,路过某个数据的输入。通常对异步的SGD很有用。
-shuffle: 随机打乱顺序,默认值为false
-new_height,new_width: 如果设置,则将图片进行resize
示例:
layer {
name: "data"
type: "ImageData"
top: "data"
top: "label"
transform_param {
mirror: false
crop_size: 227
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
image_data_param {
source: "examples/_temp/file_list.txt"
batch_size: 50
new_height: 256
new_width: 256
}
}
5、数据来源于Windows
层类型:WindowData
必须设置的参数:
-source: 一个文本文件的名字
-batch_size: 每一次处理的数据个数,即图片数
示例:
layer {
name: "data"
type: "WindowData"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
window_data_param {
source: "examples/finetune_pascal_detection/window_file_2007_trainval.txt"
batch_size: 128
fg_threshold: 0.5
bg_threshold: 0.5
fg_fraction: 0.25
context_pad: 16
crop_mode: "warp"
}
}
视觉层(Vision Layers)及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
-lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
-num_output: 卷积核(filter)的个数
-kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
-stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
-pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
-weight_filler: 权值初始化。 默认为“constant”,值全为0,很多时候我们用”xavier”算法来进行初始化,也可以设置为”gaussian”
-bias_filler: 偏置项的初始化。一般设置为”constant”,值全为0。
-bias_term: 是否开启偏置项,默认为true, 开启
-group: 分组,默认为1组。如果大于1,我们限制卷积的连接操作在一个子集内。如果我们根据图像的通道来分组,那么第i个输出分组只能与第i个输入分组进行连接。
输入:nc0w0*h0
输出:nc1w1*h1
其中,c1就是参数中的num_output,生成的特征图个数
w1=(w0+2*pad-kernel_size)/stride+1;
h1=(h0+2*pad-kernel_size)/stride+1;
如果设置stride为1,前后两次卷积部分存在重叠。如果设置pad=(kernel_size-1)/2,则运算后,宽度和高度不变。
示例:
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
2、Pooling层
也叫池化层,为了减少运算量和数据维度而设置的一种层。
层类型:Pooling
必须设置的参数:
-kernel_size: 池化的核大小。也可以用kernel_h和kernel_w分别设定。
其它参数:
-pool: 池化方法,默认为MAX。目前可用的方法有MAX, AVE, 或STOCHASTIC
-pad: 和卷积层的pad的一样,进行边缘扩充。默认为0
-stride: 池化的步长,默认为1。一般我们设置为2,即不重叠。也可以用stride_h和stride_w来设置。
示例:
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
输入:ncw0*h0
输出:ncw1*h1
和卷积层的区别就是其中的c保持不变
w1=(w0+2*pad-kernel_size)/stride+1;
h1=(h0+2*pad-kernel_size)/stride+1;
如果设置stride为2,前后两次卷积部分不重叠。100100的特征图池化后,变成5050.
3、Local Response Normalization (LRN)层
此层是对一个输入的局部区域进行归一化,达到“侧抑制”的效果。可去搜索AlexNet或GoogLenet,里面就用到了这个功能
层类型:LRN
参数:全部为可选,没有必须
-local_size: 默认为5。如果是跨通道LRN,则表示求和的通道数;如果是在通道内LRN,则表示求和的正方形区域长度。
-alpha: 默认为1,归一化公式中的参数。
-beta: 默认为5,归一化公式中的参数。
-norm_region: 默认为ACROSS_CHANNELS。有两个选择,ACROSS_CHANNELS表示在相邻的通道间求和归一化。WITHIN_CHANNEL表示在一个通道内部特定的区域内进行求和归一化。与前面的local_size参数对应。
归一化公式:对于每一个输入, 去除以$\left ( 1+\left ( \alpha /n \right ) \sum_{i}x_{i}^{2}\right )^{\beta }$,得到归一化后的输出
示例:
layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
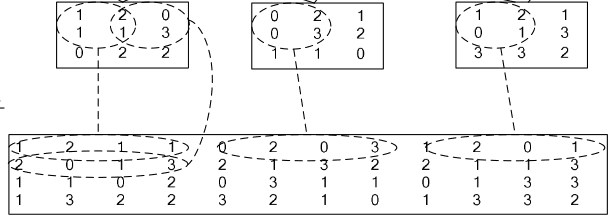
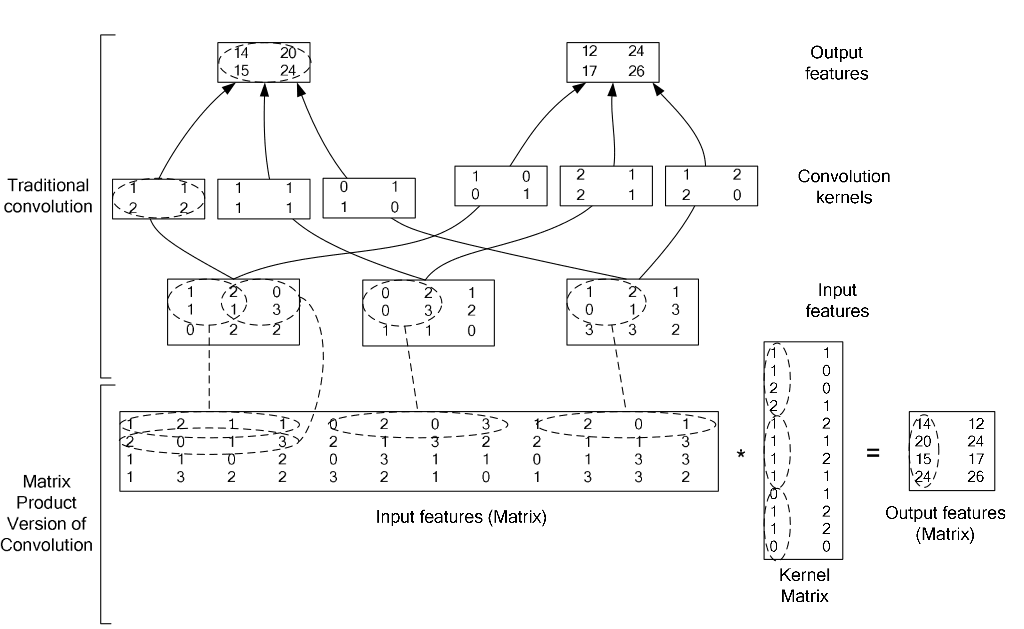
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的。从bottom得到一个blob数据输入,运算后,从top输入一个blob数据。在运算过程中,没有改变数据的大小,即输入和输出的数据大小是相等的。
输入:nch*w
输出:nch*w
常用的激活函数有sigmoid, tanh,relu等,下面分别介绍。
1、Sigmoid
对每个输入数据,利用sigmoid函数执行操作。这种层设置比较简单,没有额外的参数。
\[S\left ( x \right )=\frac{1}{1+e^{-x}}\]层类型:Sigmoid
示例:
layer {
name: "encode1neuron"
bottom: "encode1"
top: "encode1neuron"
type: "Sigmoid"
}
2、ReLU / Rectified-Linear and Leaky-ReLU
ReLU是目前使用最多的激活函数,主要因为其收敛更快,并且能保持同样效果。
标准的ReLU函数为max(x, 0),当x>0时,输出x; 当x<=0时,输出0
f(x)=max(x,0)
层类型:ReLU
可选参数:
-negative_slope:默认为0. 对标准的ReLU函数进行变化,如果设置了这个值,那么数据为负数时,就不再设置为0,而是用原始数据乘以negative_slope
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
RELU层支持in-place计算,这意味着bottom的输出和输入相同以避免内存的消耗。
3、TanH / Hyperbolic Tangent
利用双曲正切函数对数据进行变换。
\[\tanh x=\frac{\sinh x}{\cosh x}=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}\]层类型:TanH
layer {
name: "layer"
bottom: "in"
top: "out"
type: "TanH"
}
4、Absolute Value
求每个输入数据的绝对值。
f(x)=Abs(x)
层类型:AbsVal
layer {
name: "layer"
bottom: "in"
top: "out"
type: "AbsVal"
}
5、Power
对每个输入数据进行幂运算
\[f\left ( x \right )=\left ( shift+scale*x \right )^{power}\]层类型:Power
可选参数:
-power: 默认为1
-scale: 默认为1
-shift: 默认为0
layer {
name: "layer"
bottom: "in"
top: "out"
type: "Power"
power_param {
power: 2
scale: 1
shift: 0
}
}
6、BNLL
binomial normal log likelihood的简称
f(x)=log(1 + exp(x))
层类型:BNLL
layer {
name: "layer"
bottom: "in"
top: "out"
type: “BNLL”
}
其它常用层及参数
本节讲解一些其它的常用层,包括:softmax_loss层,Inner Product层,accuracy层,reshape层和dropout层及其它们的参数配置。
1、softmax-loss
softmax-loss层和softmax层计算大致是相同的。softmax是一个分类器,计算的是类别的概率(Likelihood),是Logistic Regression 的一种推广。Logistic Regression 只能用于二分类,而softmax可以用于多分类。
softmax与softmax-loss的区别:
softmax计算公式:
\[P_{j}=\frac{e_{j}^{o}}{\sum_{j}e^{o_{k}}}\]而softmax-loss计算公式:
\[L=-\sum_{j}y_{j}logp_{j}\]用户可能最终目的就是得到各个类别的概率似然值,这个时候就只需要一个 Softmax层,而不一定要进行softmax-Loss 操作;或者是用户有通过其他什么方式已经得到了某种概率似然值,然后要做最大似然估计,此时则只需要后面的 softmax-Loss 而不需要前面的 Softmax 操作。因此提供两个不同的 Layer 结构比只提供一个合在一起的 Softmax-Loss Layer 要灵活许多。
不管是softmax layer还是softmax-loss layer,都是没有参数的,只是层类型不同而以
softmax-loss layer:输出loss值
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip1"
bottom: "label"
top: "loss"
}
softmax layer: 输出似然值
layers {
bottom: "cls3_fc"
top: "prob"
name: "prob"
type: “Softmax"
}
2、Inner Product
全连接层,把输入当作成一个向量,输出也是一个简单向量(把输入数据blobs的width和height全变为1)。
输入: nc0h*w
输出: nc11*1
全连接层实际上也是一种卷积层,只是它的卷积核大小和原数据大小一致。因此它的参数基本和卷积层的参数一样。
层类型:InnerProduct
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
必须设置的参数:
-num_output: 过滤器(filfter)的个数
其它参数:
-weight_filler: 权值初始化。 默认为“constant”,值全为0,很多时候我们用”xavier”算法来进行初始化,也可以设置为”gaussian”
-bias_filler: 偏置项的初始化。一般设置为”constant”,值全为0。
-bias_term: 是否开启偏置项,默认为true, 开启
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
3、accuracy
输出分类(预测)精确度,只有test阶段才有,因此需要加入include参数。
层类型:Accuracy
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
4、reshape
在不改变数据的情况下,改变输入的维度。
层类型:Reshape
先来看例子
layer {
name: "reshape"
type: "Reshape"
bottom: "input"
top: "output"
reshape_param {
shape {
dim: 0 # copy the dimension from below
dim: 2
dim: 3
dim: -1 # infer it from the other dimensions
}
}
}
有一个可选的参数组shape, 用于指定blob数据的各维的值(blob是一个四维的数据:ncw*h)。
-dim:0 表示维度不变,即输入和输出是相同的维度。
-dim:2 或 dim:3 将原来的维度变成2或3
-dim:-1 表示由系统自动计算维度。数据的总量不变,系统会根据blob数据的其它三维来自动计算当前维的维度值 。
假设原数据为:6432828, 表示64张3通道的2828的彩色图片
经过reshape变换:
reshape_param {
shape {
dim: 0
dim: 0
dim: 14
dim: -1
}
}
输出数据为:64314*56
5、Dropout
Dropout是一个防止过拟合的trick。可以随机让网络某些隐含层节点的权重不工作。
先看例子:
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7-conv"
top: "fc7-conv"
dropout_param {
dropout_ratio: 0.5
}
}
只需要设置一个dropout_ratio就可以了。
还有其它更多的层,但用的地方不多,就不一一介绍了。
随着深度学习的深入,各种各样的新模型会不断的出现,因此对应的各种新类型的层也在不断的出现。这些新出现的层,我们只有在等caffe更新到新版本后,再去慢慢地摸索了。
Blob,Layer and Net以及对应配置文件的编写
深度网络(net)是一个组合模型,它由许多相互连接的层(layers)组合而成。Caffe就是组建深度网络的这样一种工具,它按照一定的策略,一层一层的搭建出自己的模型。它将所有的信息数据定义为blobs,从而进行便利的操作和通讯。Blob是caffe框架中一种标准的数组,一种统一的内存接口,它详细描述了信息是如何存储的,以及如何在层之间通讯的。
1、blob
Blobs封装了运行时的数据信息,提供了CPU和GPU的同步。从数学上来说, Blob就是一个N维数组。它是caffe中的数据操作基本单位,就像matlab中以矩阵为基本操作对象一样。只是矩阵是二维的,而Blob是N维的。N可以是2,3,4等等。对于图片数据来说,Blob可以表示为(NCH*W)这样一个4D数组。其中N表示图片的数量,C表示图片的通道数,H和W分别表示图片的高度和宽度。当然,除了图片数据,Blob也可以用于非图片数据。比如传统的多层感知机,就是比较简单的全连接网络,用2D的Blob,调用innerProduct层来计算就可以了。
在模型中设定的参数,也是用Blob来表示和运算。它的维度会根据参数的类型不同而不同。比如:在一个卷积层中,输入一张3通道图片,有96个卷积核,每个核大小为1111,因此这个Blob是9631111. 而在一个全连接层中,假设输入1024通道图片,输出1000个数据,则Blob为1000*1024
2、layer
层是网络模型的组成要素和计算的基本单位。层的类型比较多,如Data,Convolution,Pooling,ReLU,Softmax-loss,Accuracy等,一个层的定义大至如下图:
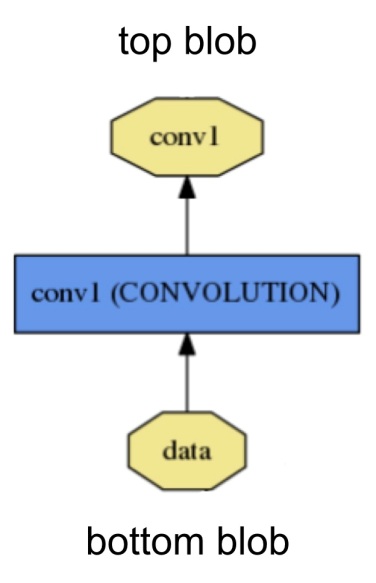
从bottom进行数据的输入 ,计算后,通过top进行输出。图中的黄色多边形表示输入输出的数据,蓝色矩形表示层。
每一种类型的层都定义了三种关键的计算:setup,forward and backword
setup: 层的建立和初始化,以及在整个模型中的连接初始化。
forward: 从bottom得到输入数据,进行计算,并将计算结果送到top,进行输出。
backward: 从层的输出端top得到数据的梯度,计算当前层的梯度,并将计算结果送到bottom,向前传递。
3、Net
就像搭积木一样,一个net由多个layer组合而成。
现给出 一个简单的2层神经网络的模型定义( 加上loss 层就变成三层了),先给出这个网络的拓扑。
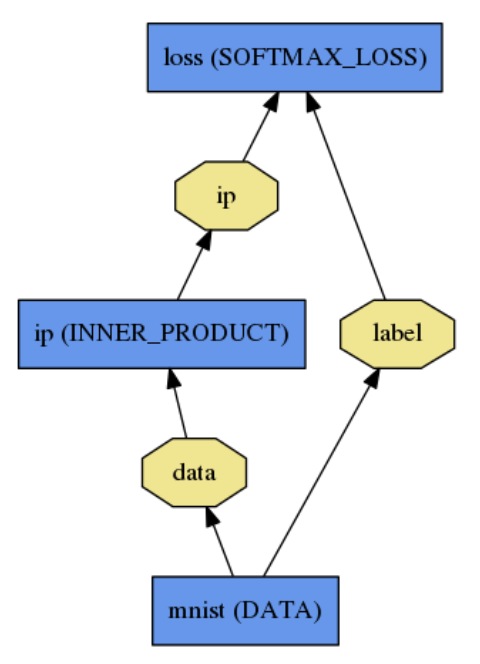
第一层:name为mnist, type为Data,没有输入(bottom),只有两个输出(top),一个为data,一个为label
第二层:name为ip,type为InnerProduct, 输入数据data, 输出数据ip
第三层:name为loss, type为SoftmaxWithLoss,有两个输入,一个为ip,一个为label,有一个输出loss,没有画出来。
对应的配置文件prototxt就可以这样写:
name: "LogReg"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
data_param {
source: "input_leveldb"
batch_size: 64
}
}
layer {
name: "ip"
type: "InnerProduct"
bottom: "data"
top: "ip"
inner_product_param {
num_output: 2
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip"
bottom: "label"
top: "loss"
}
第一行将这个模型取名为LogReg, 然后是三个layer的定义,参数都比较简单,只列出必须的参数。具体的参数定义可参见本系列的前几篇文章
solver及其配置
solver算是caffe的核心的核心,它协调着整个模型的运作。caffe程序运行必带的一个参数就是solver配置文件。运行代码一般为
caffe train --solver=*_slover.prototxt
在Deep Learning中,往往loss function是非凸的,没有解析解,我们需要通过优化方法来求解。solver的主要作用就是交替调用前向(forward)算法和后向(backward)算法来更新参数,从而最小化loss,实际上就是一种迭代的优化算法。
到目前的版本,caffe提供了六种优化算法来求解最优参数,在solver配置文件中,通过设置type类型来选择。
• Stochastic Gradient Descent (type: “SGD”),
• AdaDelta (type: “AdaDelta”),
• Adaptive Gradient (type: “AdaGrad”),
• Adam (type: “Adam”),
• Nesterov’s Accelerated Gradient (type: “Nesterov”) and
• RMSprop (type: “RMSProp”)
具体的每种方法的介绍,请看本系列的下一篇文章, 本文着重介绍solver配置文件的编写。
Solver的流程:
-
设计好需要优化的对象,以及用于学习的训练网络和用于评估的测试网络。(通过调用另外一个配置文件prototxt来进行)
-
通过forward和backward迭代的进行优化来跟新参数。
-
定期的评价测试网络。 (可设定多少次训练后,进行一次测试)
-
在优化过程中显示模型和solver的状态
在每一次的迭代过程中,solver做了这几步工作:
1、调用forward算法来计算最终的输出值,以及对应的loss
2、调用backward算法来计算每层的梯度
3、根据选用的slover方法,利用梯度进行参数更新
4、记录并保存每次迭代的学习率、快照,以及对应的状态。
接下来,我们先来看一个实例:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
base_lr: 0.01
momentum: 0.9
type: SGD
weight_decay: 0.0005
lr_policy: "inv"
gamma: 0.0001
power: 0.75
display: 100
max_iter: 20000
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
solver_mode: CPU
接下来,我们对每一行进行详细解译:
net: "examples/mnist/lenet_train_test.prototxt"
设置深度网络模型。每一个模型就是一个net,需要在一个专门的配置文件中对net进行配置,每个net由许多的layer所组成。
注意的是:文件的路径要从caffe的根目录开始,其它的所有配置都是这样。
也可用train_net和test_net来对训练模型和测试模型分别设定。例如:
train_net: "examples/hdf5_classification/logreg_auto_train.prototxt"
test_net: "examples/hdf5_classification/logreg_auto_test.prototxt"
接下来第二行:
test_iter: 100
这个要与test layer中的batch_size结合起来理解。mnist数据中测试样本总数为10000,一次性执行全部数据效率很低,因此我们将测试数据分成几个批次来执行,每个批次的数量就是batch_size。假设我们设置batch_size为100,则需要迭代100次才能将10000个数据全部执行完。因此test_iter设置为100。执行完一次全部数据,称之为一个epoch
test_interval: 500
测试间隔。也就是每训练500次,才进行一次测试。
base_lr: 0.01
lr_policy: "inv"
gamma: 0.0001
power: 0.75
这四行可以放在一起理解,用于学习率的设置。只要是梯度下降法来求解优化,都会有一个学习率,也叫步长。base_lr用于设置基础学习率,在迭代的过程中,可以对基础学习率进行调整。怎么样进行调整,就是调整的策略,由lr_policy来设置。
lr_policy可以设置为下面这些值,相应的学习率的计算为:
• - fixed: 保持base_lr不变.
• - step: 如果设置为step,则还需要设置一个stepsize, 返回 base_lr * gamma ^ (floor(iter / stepsize)),其中iter表示当前的迭代次数
• - exp: 返回base_lr * gamma ^ iter, iter为当前迭代次数
• - inv: 如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power)
• - multistep: 如果设置为multistep,则还需要设置一个stepvalue。这个参数和step很相似,step是均匀等间隔变化,而multistep则是根据 stepvalue值变化
• - poly: 学习率进行多项式误差, 返回 base_lr (1 - iter/max_iter) ^ (power)
• - sigmoid: 学习率进行sigmod衰减,返回 base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
multistep示例:
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "multistep"
gamma: 0.9
stepvalue: 5000
stepvalue: 7000
stepvalue: 8000
stepvalue: 9000
stepvalue: 9500
接下来的参数:
momentum :0.9
上一次梯度更新的权重
type: SGD
优化算法选择。这一行可以省掉,因为默认值就是SGD。总共有六种方法可选择,在本文的开头已介绍。
weight_decay: 0.0005
权重衰减项,防止过拟合的一个参数。
display: 100
每训练100次,在屏幕上显示一次。如果设置为0,则不显示。
max_iter: 20000
最大迭代次数。这个数设置太小,会导致没有收敛,精确度很低。设置太大,会导致震荡,浪费时间。
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
快照。将训练出来的model和solver状态进行保存,snapshot用于设置训练多少次后进行保存,默认为0,不保存。snapshot_prefix设置保存路径。
还可以设置snapshot_diff,是否保存梯度值,默认为false,不保存。
也可以设置snapshot_format,保存的类型。有两种选择:HDF5 和BINARYPROTO ,默认为BINARYPROTO
solver_mode: CPU
设置运行模式。默认为GPU,如果你没有GPU,则需要改成CPU,否则会出错。
注意:以上的所有参数都是可选参数,都有默认值。根据solver方法(type)的不同,还有一些其它的参数,在此不一一列举。
solver优化方法
上文提到,到目前为止,caffe总共提供了六种优化方法:
• Stochastic Gradient Descent (type: “SGD”),
• AdaDelta (type: “AdaDelta”),
• Adaptive Gradient (type: “AdaGrad”),
• Adam (type: “Adam”),
• Nesterov’s Accelerated Gradient (type: “Nesterov”) and
• RMSprop (type: “RMSProp”)
Solver就是用来使loss最小化的优化方法。对于一个数据集D,需要优化的目标函数是整个数据集中所有数据loss的平均值。
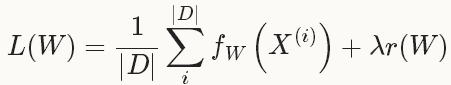
其中,fW(x(i))计算的是数据x(i)上的loss, 先将每个单独的样本x的loss求出来,然后求和,最后求均值。 r(W)是正则项(weight_decay),为了减弱过拟合现象。
如果采用这种Loss 函数,迭代一次需要计算整个数据集,在数据集非常大的这情况下,这种方法的效率很低,这个也是我们熟知的梯度下降采用的方法。
| 在实际中,通过将整个数据集分成几批(batches), 每一批就是一个mini-batch,其数量(batch_size)为N« | D | ,此时的loss 函数为: |
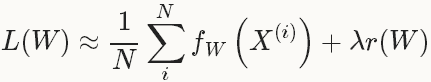
有了loss函数后,就可以迭代的求解loss和梯度来优化这个问题。在神经网络中,用forward pass来求解loss,用backward pass来求解梯度。
在caffe中,默认采用的Stochastic Gradient Descent(SGD)进行优化求解。后面几种方法也是基于梯度的优化方法(like SGD),因此本文只介绍一下SGD。其它的方法,有兴趣的同学,可以去看文献原文。
1、Stochastic gradient descent(SGD)
随机梯度下降(Stochastic gradient descent)是在梯度下降法(gradient descent)的基础上发展起来的,梯度下降法也叫最速下降法,具体原理在网易公开课《机器学习》中,吴恩达教授已经讲解得非常详细。SGD在通过负梯度 $\bigtriangledown L\left ( W \right )$和上一次的权重更新值Vt的线性组合来更新W,迭代公式如下:
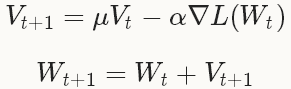
其中,$\alpha $是负梯度的学习率(base_lr),$\mu $ 是上一次梯度值的权重(momentum),用来加权之前梯度方向对现在梯度下降方向的影响。这两个参数需要通过tuning来得到最好的结果,一般是根据经验设定的。如果你不知道如何设定这些参数,可以参考相关的论文。
在深度学习中使用SGD,比较好的初始化参数的策略是把学习率设为0.01左右(base_lr: 0.01),在训练的过程中,如果loss开始出现稳定水平时,对学习率乘以一个常数因子(gamma),这样的过程重复多次。
对于momentum,一般取值在0.5–0.99之间。通常设为0.9,momentum可以让使用SGD的深度学习方法更加稳定以及快速。
关于更多的momentum,请参看Hinton的《A Practical Guide to Training Restricted Boltzmann Machines》。
实例:
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 1000
max_iter: 3500
momentum: 0.9
lr_policy设置为step,则学习率的变化规则为 base_lr * gamma ^ (floor(iter / stepsize))
即前1000次迭代,学习率为0.01; 第1001-2000次迭代,学习率为0.001; 第2001-3000次迭代,学习率为0.00001,第3001-3500次迭代,学习率为10-5
上面的设置只能作为一种指导,它们不能保证在任何情况下都能得到最佳的结果,有时候这种方法甚至不work。如果学习的时候出现diverge(比如,你一开始就发现非常大或者NaN或者inf的loss值或者输出),此时你需要降低base_lr的值(比如,0.001),然后重新训练,这样的过程重复几次直到你找到可以work的base_lr。
2、AdaDelta
AdaDelta是一种”鲁棒的学习率方法“,是基于梯度的优化方法(like SGD)。
具体的介绍文献:
M. Zeiler ADADELTA: AN ADAPTIVE LEARNING RATE METHOD. arXiv preprint, 2012.
示例:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
base_lr: 1.0
lr_policy: "fixed"
momentum: 0.95
weight_decay: 0.0005
display: 100
max_iter: 10000
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet_adadelta"
solver_mode: GPU
type: "AdaDelta"
delta: 1e-6
从最后两行可看出,设置solver type为Adadelta时,需要设置delta的值。
3、AdaGrad
自适应梯度(adaptive gradient)是基于梯度的优化方法(like SGD)
具体的介绍文献:
Duchi, E. Hazan, and Y. Singer. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. The Journal of Machine Learning Research, 2011.
示例:
net: "examples/mnist/mnist_autoencoder.prototxt"
test_state: { stage: 'test-on-train' }
test_iter: 500
test_state: { stage: 'test-on-test' }
test_iter: 100
test_interval: 500
test_compute_loss: true
base_lr: 0.01
lr_policy: "fixed"
display: 100
max_iter: 65000
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "examples/mnist/mnist_autoencoder_adagrad_train"
# solver mode: CPU or GPU
solver_mode: GPU
type: "AdaGrad"
4、Adam
是一种基于梯度的优化方法(like SGD)。
具体的介绍文献:
D. Kingma, J. Ba. Adam: A Method for Stochastic Optimization. International Conference for Learning Representations, 2015.
5、NAG
Nesterov 的加速梯度法(Nesterov’s accelerated gradient)作为凸优化中最理想的方法,其收敛速度非常快。
具体的介绍文献:
I. Sutskever, J. Martens, G. Dahl, and G. Hinton. On the Importance of Initialization and Momentum in Deep Learning. Proceedings of the 30th International Conference on Machine Learning, 2013.
示例:
net: "examples/mnist/mnist_autoencoder.prototxt"
test_state: { stage: 'test-on-train' }
test_iter: 500
test_state: { stage: 'test-on-test' }
test_iter: 100
test_interval: 500
test_compute_loss: true
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 10000
display: 100
max_iter: 65000
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "examples/mnist/mnist_autoencoder_nesterov_train"
momentum: 0.95
# solver mode: CPU or GPU
solver_mode: GPU
type: "Nesterov"
6、RMSprop
RMSprop是Tieleman在一次 Coursera课程演讲中提出来的,也是一种基于梯度的优化方法(like SGD)
具体的介绍文献:
T. Tieleman, and G. Hinton. RMSProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning.Technical report, 2012.
示例:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
base_lr: 1.0
lr_policy: "fixed"
momentum: 0.95
weight_decay: 0.0005
display: 100
max_iter: 10000
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet_adadelta"
solver_mode: GPU
type: "RMSProp"
rms_decay: 0.98
最后两行,需要设置rms_decay值。
看我写的辛苦求打赏啊!!!有学术讨论和指点请加微信manutdzou,注明
