
Show, Attend and Tell Neural Image Caption Generation with Visual Attention
输入:图像$I$
特征(annotation):$\left (a_1…a_i…a_L \right)$
上下文(context):$\left (z_1…z_t…z_C \right)$
输出(caption):$\left (y_1…y_t…y_C \right)$
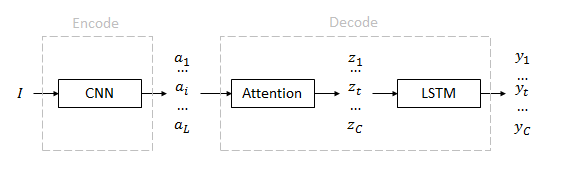
I是输入的彩色图像
$a_i$是由训练好的卷积网络获取的不同图像区域的特征,用于描述图像的不同区域
$z_t$是一个D维特征,共有C个,表示每个单词对应的上下文
输出有顺序的一句caption,句子长度C不定,每个单词$y_t$是一个K维概率,K是字典的大小
算法流程
首先利用卷积网络获取一组图片的描述features,输入图像I归一化到224×224。特征a直接使用现成的VGG网络中conv5_3层的14×14×512维特征。区域数量L=14×14=196,维度D=512。
利用图片的描述features初始化lstm的状态和隐变量h和c
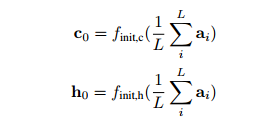
利用图像特征的映射features_proj和前一时刻的隐变量$h_{t-1}$经过MLP的和生成attention来获取当前的上下文信息context和权重alpha
def _attention_layer(self, features, features_proj, h, reuse=False):
with tf.variable_scope('attention_layer', reuse=reuse):
w = tf.get_variable('w', [self.H, self.D], initializer=self.weight_initializer)
b = tf.get_variable('b', [self.D], initializer=self.const_initializer)
w_att = tf.get_variable('w_att', [self.D, 1], initializer=self.weight_initializer)
h_att = tf.nn.relu(features_proj + tf.expand_dims(tf.matmul(h, w), 1) + b) # (N, L, D)
out_att = tf.reshape(tf.matmul(tf.reshape(h_att, [-1, self.D]), w_att), [-1, self.L]) # (N, L)
alpha = tf.nn.softmax(out_att)
context = tf.reduce_sum(features * tf.expand_dims(alpha, 2), 1, name='context') #(N, D)
return context, alpha
利用当前的上下文信息context和上一时刻描述的词的Embedding x的concat信息以及上一时刻的状态$h_{t-1}$和$c_{t-1}$输入lstm来获取当前时刻的$h_t$和$c_t$
with tf.variable_scope('lstm', reuse=(t!=0)):
_, (c, h) = lstm_cell(inputs=tf.concat( [x[:,t,:], context],1), state=[c, h])
利用当前的上下文信息context和上一时刻描述的词的Embedding x以及当前时刻的隐状态$h$来编码预测当前时刻描述的词,见原文公式,并且代码实现上严格参照了论文的表述
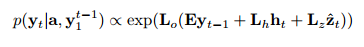
def _decode_lstm(self, x, h, context, dropout=False, reuse=False):
with tf.variable_scope('logits', reuse=reuse):
w_h = tf.get_variable('w_h', [self.H, self.M], initializer=self.weight_initializer)
b_h = tf.get_variable('b_h', [self.M], initializer=self.const_initializer)
w_out = tf.get_variable('w_out', [self.M, self.V], initializer=self.weight_initializer)
b_out = tf.get_variable('b_out', [self.V], initializer=self.const_initializer)
if dropout:
h = tf.nn.dropout(h, 0.5)
h_logits = tf.matmul(h, w_h) + b_h
if self.ctx2out:
w_ctx2out = tf.get_variable('w_ctx2out', [self.D, self.M], initializer=self.weight_initializer)
h_logits += tf.matmul(context, w_ctx2out)
if self.prev2out:
h_logits += x
h_logits = tf.nn.tanh(h_logits)
if dropout:
h_logits = tf.nn.dropout(h_logits, 0.5)
out_logits = tf.matmul(h_logits, w_out) + b_out
return out_logits
看我写的辛苦求打赏啊!!!有学术讨论和指点请加微信manutdzou,注明
